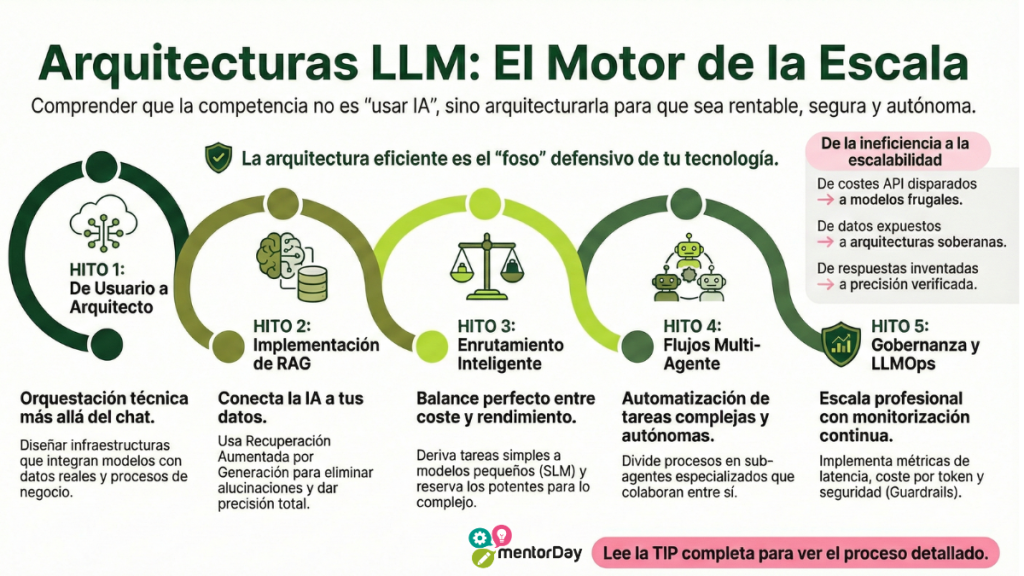
BLOQUE 2. AUTODIAGNÓSTICO – TU PUNTO DE PARTIDA
Evalúa tu nivel actual en Arquitecturas LLM.
Indicadores conductuales observables:
1. Orquesto flujos de trabajo multi-agente en mis operaciones. (Lo hago / A veces / No lo hago)
2. Diferencio cuándo usar ajuste fino (fine-tuning) versus cuándo usar RAG. (Lo hago / A veces / No lo hago)
3. Monitorizo el coste por token y la latencia en mis implementaciones de IA. (Lo hago / A veces / No lo hago)
4. Aplico técnicas de compresión de contexto y poda de información. (Lo hago / A veces / No lo hago)
5. Implemento medidas de seguridad («guardrails») contra inyección de prompts. (Lo hago / A veces / No lo hago)
Medición cuantitativa (KPIs de Arquitectura):
• Ratio de Alucinación: % de respuestas de la IA no fundamentadas en los datos aportados.
• Coste por Tarea: (Coste total API / Tareas completadas con éxito).
• Latencia Media (Time to First Token): Milisegundos desde que el usuario pregunta hasta que la IA empieza a responder.
Autoevaluación Likert (Valora del 1 al 5):
1. Comprendo cómo estructurar un pipeline de RAG (búsqueda vectorial + generador).
2. Conozco las diferencias técnicas y de coste entre usar modelos comerciales (SaaS) y modelos open-source en servidores propios.
3. Sé utilizar frameworks de evaluación y monitoreo (como MLflow o Opik) para medir el rendimiento de mis prompts y modelos.
4. Evalúo sistemas de razonamiento y enrutamiento dinámico según el presupuesto por consulta.
5. Gestiono de manera estructurada los datos (ETLs, vectorización) para alimentar la memoria de trabajo de la IA.
Cálculo de puntuación global: Suma tus respuestas (máximo 25, mínimo 5). Aplica la fórmula: (Media Likert – 1) × 25 = Tu puntuación de 0 a 100.
• 0–39 Bajo (Novato): Solo usas ChatGPT como usuario final. No hay integración técnica en tu negocio.
• 40–59 Medio (Practicante): Usas APIs conectadas a tu software, pero de forma rígida y costosa.
• 60–79 Alto (Arquitecto): Diseñas sistemas con RAG, optimizas tokens e integras bases de datos.
• 80–100 Excelente (Maestro): Construyes flujos multi-agente, balanceas modelos según coste/precisión y mides el impacto con LLMOps riguroso.
Mini SJT (Test de Juicio Situacional):
• Situación 1: Tu factura de la API de un LLM comercial se ha triplicado este mes debido a un aumento de tráfico, pero el 80% de las consultas son respuestas repetitivas de baja complejidad.
◦ A) Limitas el uso a los clientes para no gastar más. (Malo: frenas el negocio).
◦ B) Cambias a una suscripción de tarifa plana superior. (Regular: no escalas eficientemente).
◦ C) Implementas un Router semántico que derive consultas sencillas a un modelo de código abierto pequeño y gratuito, y reserve el de pago solo para consultas complejas. (MEJOR OPCIÓN).
• Situación 2: Tu asistente de IA médico inventa diagnósticos de vez en cuando (alucinaciones).
◦ A) Añades al prompt: «No inventes cosas». (Malo: no es una barrera arquitectónica sólida).
◦ B) Implementas un sistema de Corrective RAG (CRAG) con evaluación de la recuperación para basar cada respuesta estrictamente en tus protocolos aprobados. (MEJOR OPCIÓN).
◦ C) Entrenas (fine-tuning) todo un modelo gigante con tus manuales. (Regular: muy costoso y el modelo aún puede alucinar o quedar desactualizado).
Red flags (Señales de alarma):
1. Ataduras (Vendor Lock-in) a un solo proveedor que cambia sus precios.
2. Pasar todo el historial de una conversación sin compresión, colapsando la ventana de contexto.
3. Ignorar la ciberseguridad y pasar datos personales identificables (PII) a APIs públicas.
4. No tener métricas de evaluación objetivas («funciona a ojo»).
Evidencias de dominio:
• Pipelines CI/CD implementados para IA.
• Sistemas de IA de tu empresa desplegados sin caídas y con costes predecibles.
• Reducción sistemática documentada de la latencia en las respuestas.
BLOQUE 3. LA COMPETENCIA EN ACCIÓN – CASOS Y CONTEXTOS
Caso de éxito:
Una plataforma SaaS de recursos humanos quería crear un asistente automatizado. Situación: Los modelos genéricos eran lentos e inseguros para datos salariales confidenciales. Acción aplicando la competencia: La empresa diseñó una arquitectura híbrida on-premise utilizando un modelo de 8B parámetros de código abierto, integrado con un pipeline RAG con búsqueda híbrida conectada a sus bases de datos internas. Resultado: Reducción del coste operativo mensual en un 90% frente a APIs comerciales, tiempo de respuesta <1 segundo y cumplimiento total de normativas de protección de datos.
Caso de carencia:
Una startup legal automatizó la revisión de contratos conectando su app a un modelo de frontera a través de una API simple. Falta de competencia: No aislaron el contexto ni utilizaron bases vectoriales. Consecuencia: Enviaban documentos gigantes en cada petición; la «podredumbre del contexto» hizo que el modelo olvidara cláusulas críticas (perdiéndose en el medio del documento), y el coste de computación llevó a la empresa a la quiebra técnica en 3 meses. Aprendizaje: La ingeniería de contexto y el particionado de datos (chunking) son innegociables.
Matriz Dónde es más necesaria:
Fase | Sector | Criticidad | Justificación |
|---|
Validación | Legal / Fintech | Alto | Tolerancia cero a alucinaciones; exige arquitecturas de RAG muy precisas. |
Crecimiento | SaaS / B2B | Alto | Los costes de API se disparan al escalar; requiere enrutamiento de modelos. |
Idea | Retail tradicional | Bajo | Las operaciones pueden validarse manualmente antes de automatizar IA. |
Escala | HealthTech | Alto | La normativa exige privacidad local y modelos frugales auditables. |
Perfiles críticos:
CTOs (Directores de Tecnología), Ingenieros de Datos y Líderes de Producto de IA. Requieren esta competencia porque la escalabilidad del negocio recae sobre sus decisiones de infraestructura.
Cuándo NO es prioritaria:
En etapas puramente de ideación donde aún no tienes validado si el cliente quiere tu producto (crear la mejor arquitectura IA del mundo no sirve si nadie necesita el servicio).
BLOQUE 4. PLAN DE ENTRENAMIENTO – CÓMO MEJORAR ARQUITECTURAS LLM
• En la 1.ª etapa del programa mentorDay: identificarás las competencias especiales para tu negocio y tendrás 1 mes para mejorarlas incorporando hábitos.
• En la 2.ª etapa: vuelve a autovalorarte; si no alcanzas el nivel requerido, decide buscar socio que la aporte, con ayuda de tu mentor. Tendrás taller, webinar y speedmentoring con un experto en tecnología.
5 Micro-hábitos accionables:
1. Curación de ruido: Cada vez que uses un chat IA, fuérzate a enviar solo el texto estrictamente necesario, entrenando tu mentalidad de «compresión de contexto».
2. Revisión de Leaderboards: Dedica 1 minuto semanal a revisar tablas de clasificación abiertas (ej. LMSYS Chatbot Arena o Hugging Face) para conocer modelos pequeños (SLMs).
3. Métricas en mente: Acostúmbrate a calcular mentalmente el coste de input/output de las interacciones que diseñas.
4. Pensamiento modular: Ante cualquier tarea, desglósala: ¿Qué parte hace una búsqueda? ¿Qué parte resume? ¿Qué parte decide?
5. Auditoría de seguridad exprés: Pregúntate diariamente: «Si este log se hiciera público, ¿incumpliríamos normativas?».
3 Ejercicios paso a paso:
• Ejercicio 1: Dibuja tu Pipeline RAG. Objetivo: Visualizar tu arquitectura. Materiales: Papel o pizarra digital (Miro). Instrucciones: Dibuja el flujo desde que el usuario hace una pregunta, cómo se busca en tu base de datos (vectorial), cómo se inyecta en el prompt y cómo responde el LLM. Criterio de éxito: Debes tener claramente separados el recuperador, la memoria y el modelo. (Variante exprés 10 min: Hazlo en 3 post-its).
• Ejercicio 2: Comparativa de Modelos. Objetivo: Entender el trade-off coste/latencia. Materiales: Excel. Instrucciones: Elige 3 modelos (ej. un GPT avanzado, un Claude rápido y un Mistral/Llama local). Calcula cuánto costaría procesar 10.000 documentos de tu empresa en cada uno. Criterio de éxito: Identificar un modelo eficiente que baje costes sin perder calidad.
• Ejercicio 3: Aislar Responsabilidades (Agentes). Objetivo: Crear flujos robustos. Instrucciones: Define un flujo de trabajo. En lugar de un mega-prompt que lo haga todo, divídelo en 3 «sub-agentes» (Ej. Agente 1 extrae datos, Agente 2 los calcula, Agente 3 redacta el correo). Criterio de éxito: Flujo documentado modularmente.
Frameworks y metodologías conectadas:
• LLMOps (MLOps para LLMs): Gestión del ciclo de vida, desde la experimentación hasta el despliegue y monitorización (ej. uso de MLflow).
• Arquitecturas de Inferencia Frugal: Modelos MatMul-free y uso de cuantización para correr modelos potentes en hardware pequeño.
• OWASP LLM Top 10: Metodología indispensable para cubrir las vulnerabilidades de seguridad.
5 Errores comunes y anti-patrones:
1. La «Navaja Suiza» (Un modelo para todo): Usar el LLM más caro para tareas de clasificación básica. Evítalo usando routers de modelos.
2. Síndrome del acaparador de contexto: Rellenar la ventana del modelo con datos inútiles, provocando que se «pierda en el medio». Evítalo usando técnicas de fragmentación y reclasificación.
3. Ausencia de memoria episódica: Agentes que no recuerdan acciones pasadas y entran en bucles. Evítalo usando bases de datos como memoria externa a largo plazo.
4. Despliegue a ciegas: No usar herramientas para medir calidad o alucinaciones sistemáticamente. Evítalo adoptando frameworks de evaluación (LLM-as-a-judge).
5. No filtrar resultados (Sanitization): Pasar respuestas crudas del LLM al usuario. Evítalo forzando salidas estructuradas (JSON) y validándolas antes de mostrarlas.
BLOQUE 5. HERRAMIENTAS Y RECURSOS DE APOYO
Para afianzar esta competencia técnica pero absolutamente estratégica, apóyate en el ecosistema emprendedor.
• Programa de aceleración mentorDay: Identifica tus competencias clave y recibe apoyo de mentores especializados (CTOs y expertos en IA). Inscripción aquí. • 3.ª etapa (mentoring anual): Al completar tu plan, mentorDay te asignará el mentor ideal (alguien experto en tecnología e IA aplicada). Más info. Plantillas / Apps fundamentales:
1. LangChain / LlamaIndex: Frameworks estándar de la industria para orquestar RAG y agentes. Sirven para no programar desde cero la conexión entre tus datos y el LLM.
2. MLflow / Opik / LangSmith: Herramientas de «Observabilidad». Sirven para registrar trazabilidad de las peticiones, costes, latencias y evaluar el desempeño en producción.
3. Ollama / LM Studio: Aplicaciones para correr y testear Modelos Pequeños y Abiertos (SLMs) en tu propio ordenador. Sirven para probar viabilidad sin gastar en APIs.
Lecturas clave:
• Documentación técnica de bases de datos vectoriales (Pinecone, Weaviate, Elastic) – Sirve para dominar el pilar del RAG.
• Patrones de Diseño para Machine Learning de Valliappa Lakshmanan – Adaptable al mundo LLM para pensar en arquitectura escalable y resiliente.
Formación recomendada:
• MOOC: Conceptos de grandes modelos lingüísticos / LLMOps en plataformas de Data Science (ej. DataCamp). Nivel: Intermedio.
• Desarrollo de aplicaciones LLM con LangChain. Nivel: Avanzado.
No te pierdas los recursos constantes: [Suscríbete al canal de YouTube de mentorDay y nuestra newsletter] para recibir píldoras actualizadas de tecnología y emprendimiento.
BLOQUE 6. ECOSISTEMA DE APOYO – COMPLEMENTA TU PERFIL
Si tu rol es CEO / Negocio puro y la arquitectura técnica se te escapa, no te estanques. Si no puedes mejorar Arquitecturas LLM con rapidez, busca un socio que la aporte.
Perfiles complementarios:
1. AI / ML Engineer: Alguien que respira Python y entiende cómo parametrizar y optimizar modelos, montar bases vectoriales y diseñar prompts sistemáticos.
2. Cloud/DevOps Engineer: Para configurar los servidores, clústeres de GPUs o pipelines CI/CD que soportan tu arquitectura de inferencia y asegurarla.
3. Data Engineer: El diseño del RAG no sirve de nada si los datos de la empresa están desordenados. Este perfil limpia y estructura tus datos (ETL) para que la IA los consuma.
Checklist para integrar estos perfiles:
• [ ] ¿He definido claramente si necesito consumir un servicio en la nube o tener un modelo propio?
• [ ] ¿El perfil técnico entiende de orquestación de datos y no solo de «escribir prompts»?
• [ ] ¿Tengo una política clara de seguridad de datos para cuando contrate al equipo técnico?
Comunidades:
• Hugging Face: La comunidad global definitiva de modelos abiertos y arquitecturas.
• GitHub (Repositorios de MLOps): Donde surgen las arquitecturas de vanguardia.
• Conecta con otros emprendedores y CTOs en el Networking mensual de mentorDay: Regístrate aquí. BLOQUE 7. TU PLAN DE ACCIÓN PERSONAL
Objetivo SMART a 30 días:
«En los próximos 30 días, migraré una tarea repetitiva de nuestro negocio desde la interfaz de ChatGPT a un flujo de RAG básico documentado en código, conectando 10 PDFs de nuestra empresa para reducir las alucinaciones al 0% y el tiempo de consulta en un 50%.»
Plan 30–60–90:
Fase | Metas Semanales / Mensuales | Métricas | Entregables |
|---|
Día 30 | Montar un flujo básico de recuperación de datos (RAG) para un caso de uso interno simple. | Precisión al buscar un dato concreto en los PDFs. | Diagrama de arquitectura y PoC (Proof of Concept) funcional. |
Día 60 | Implementar métricas de observabilidad y evaluar cambiar el modelo comercial por un SLM (modelo pequeño) open-source. | Reducción de latencia en % y reducción de coste. | Dashboard de MLflow o LangSmith activo con logs reales. |
Día 90 | Automatizar un proceso crítico del cliente usando un enrutador inteligente de prompts. | Ratio de finalización de tarea sin error humano. | Sistema Multi-agente en producción con «guardrails» de seguridad. |
KPIs de progreso:
1. Coste total de inferencia AI por cada 1.000 interacciones.
2. Tiempo de latencia (respuesta).
3. Score de calidad automatizado (usando LLM-as-a-judge).
Próximo paso en 5 minutos:
Dibuja en una hoja de papel los 3 pasos clave de cómo se respondería una duda técnica en tu empresa hoy. Luego marca dónde la IA buscaría el dato, y dónde generaría la respuesta. Acabas de diseñar tu primera separación de arquitectura.
Copia y pega tu resumen en el área privada y en el entregable ‘Plan de recursos humanos, desarrollo y crecimiento personal’ del programa mentorDay.
BLOQUE 8. MAPA DE ADECUACIÓN ESTRATÉGICA DE ARQUITECTURAS LLM
El dominio de Arquitecturas LLM es crítico cuando escalas la IA en operaciones, superas la fase de prototipo manual y la eficiencia (costes/seguridad) se vuelve imperativa.
8.1. Cuándo aplicar Arquitecturas LLM
• Sobrecoste de APIs: Cuando el gasto en OpenAI/Anthropic erosiona tu margen → diseña enrutamiento a modelos open-source más eficientes.
• Problemas de calidad y alucinaciones: Cuando la IA falla en respuestas basadas en hechos de tu empresa → arquitectura RAG con segmentación semántica.
• Fugas de privacidad/cumplimiento normativo: Cuando operas datos médicos, legales o financieros → arquitectura de despliegue on-premise (local) aislada de la nube pública.
• Complejidad en tareas: Cuando un solo prompt fracasa repetidamente → diseño de orquestación multi-agente.
8.2. Dónde es más necesaria (Matriz Fase × Sector × Modelo × Innovación)
Sector | Modelo de negocio | Fase del proyecto | Grado de innovación | Criticidad | Justificación |
|---|
Tech (SaaS AI) | Suscripción | Crecimiento | Sustancial | Alta | Los márgenes mueren si no orquestas de forma óptima el uso de las APIs. |
Legal / Salud | Licencia / Servicios | Validación | Incremental | Alta | Privacidad de datos absoluta; obliga a modelos desplegados en entornos seguros (Zero-Trust). |
B2B Industrial | HW+Servicio | Escala | Radical | Media | Relevante para integrar IA en el Edge (IoT) con modelos muy ligeros. |
Retail/Ecom. | Transaccional | Validación | Incremental | Media | Optimiza motores de recomendación híbridos y búsqueda semántica rápida. |
Servicios Trad. | One-off | Idea | Incremental | Baja | Antes de crear sistemas complejos, valida que el cliente paga por el servicio manual. |
Impacto (ONG) | Suscripción/Donación | Crecimiento | Sustancial | Media | Útil para análisis de grandes volúmenes de datos con bajo presupuesto usando open-source. |
8.3. Tecnologías a incorporar para potenciar la competencia
• Bases de Datos Vectoriales (Pinecone, Elasticsearch) → Pilar de la recuperación de contexto (RAG).
• Frameworks de Orquestación (LangChain, LlamaIndex) → Coordinación de agentes y herramientas.
• Observabilidad LLMOps (Opik, MLflow, LangSmith) → Dashboards para métricas de latencia, coste y calidad de respuestas.
• Cloud & Edge Computing (AWS Bedrock, Ollama, vLLM) → Despliegue de los modelos y ajuste fino eficiente (LoRA).
• Sistemas de Enrutamiento (R2-Router) → Selección dinámica del LLM más barato que pueda cumplir el estándar de calidad en tiempo real.
8.4. Tamaño y economía del proyecto (Umbrales críticos)
Variable | Rango recomendado | Umbral de prioridad | Nota/por qué |
|---|
Gastos API (Coste) | 0 – 100€ · 100 – 500€ · >500€ | >500€/mes | La arquitectura debe priorizar reducir costes con SLMs y enrutamiento. |
Complejidad de Datos | Públicos · Internos · Confidenciales | Confidenciales | Si gestionas datos PII/sensibles, la arquitectura segura es innegociable por normativa (AI Act). |
Volumen Consultas | 10/día · 1.000/día · >10k/día | >1.000/día | La latencia y el coste exigen optimizar el contexto y usar cachés semánticas. |
Precisión requerida | Baja (Creatividad) · Alta (Decisión crítica) | Alta (Decisión) | RAG avanzado y flujos deterministas pasan a ser obligación vital. |
8.5. Reglas de decisión e Índice de Adecuación (IA)
1. Puntuación: Sector = 3 (Si es tech/salud/legal) | Modelo = 3 (Si es SaaS/Escalable) | Fase = 3 (Crecimiento/Escala) | Innovación = 3 (Radical o central en IA).
2. IA (media ponderada): IA = (Sector·0,25 + Modelo·0,25 + Fase·0,25 + Innovación·0,25).
3. Ajustes: Si manejas datos altamente regulados (+0,6 al instante). Si el coste de inferencia daña el margen (+0,4).
4. Umbrales: IA ≥ 2,6 → ALTA | 2,0–2,59 → MEDIA | < 2,0 → BAJA.
5. Conclusión operativa: Si tu empresa basa su core en IA o gestiona datos privados en volumen, Arquitecturas LLM es prioridad ALTA para garantizar márgenes y cumplimiento legal. DECISIÓN: Audita hoy tu flujo de llamadas a la IA y tus facturas de API.
8.6. Siguiente paso
Mide el «Time to First Token» y el coste de las últimas 100 interacciones de IA en tu empresa. Si no sabes cómo, necesitas orquestación urgente. Empieza tu entrenamiento hoy.
Tabla-Resumen Ejecutiva
Qué es | Cómo medir | Riesgos si es baja | 3 hábitos | 3 ejercicios | 3 herramientas |
|---|
Diseñar la infraestructura y orquestación de IA (modelos, RAG, agentes) de forma eficiente y segura. | Latencia (ms), Coste por tarea completada, % Alucinaciones, Éxito de recuperación. | Fugas de datos (PII), sobrecostes en APIs que rompen el negocio, pérdida de fiabilidad del producto. | 1. Filtrar el «ruido» al dar contexto.<br>2. Revisar leaderboards de modelos SLM.<br>3. Pensar en sub-agentes modulares. | 1. Dibuja tu Pipeline RAG.<br>2. Compara costes de 3 APIs de IA.<br>3. Aíslar responsabilidades en un flujo. | 1. LangChain / LlamaIndex (orquestación).<br>2. MLflow / Opik (LLMOps).<br>3. Pinecone / Elasticsearch (vectores). |
Mapa de riesgos operativos:
• Si es crítica y está baja: Tus competidores usarán modelos frugales que cuestan un 10% de lo que tú gastas en OpenAI, sacándote del mercado por precio. Tus clientes corporativos bloquearán tus contratos al no superar las auditorías de seguridad y privacidad.
Competencias relacionadas (Sinergias):
• Ciberseguridad: Trabajo en paralelo para proteger las APIs, encriptar datos y aplicar metodologías OWASP. • Gestión de innovación: Para iterar rápidamente entre diferentes modelos en un mercado que cambia semanalmente.