BLOQUE 1. ¿QUÉ ES Ingeniería de datos Y POR QUÉ ES CRUCIAL?
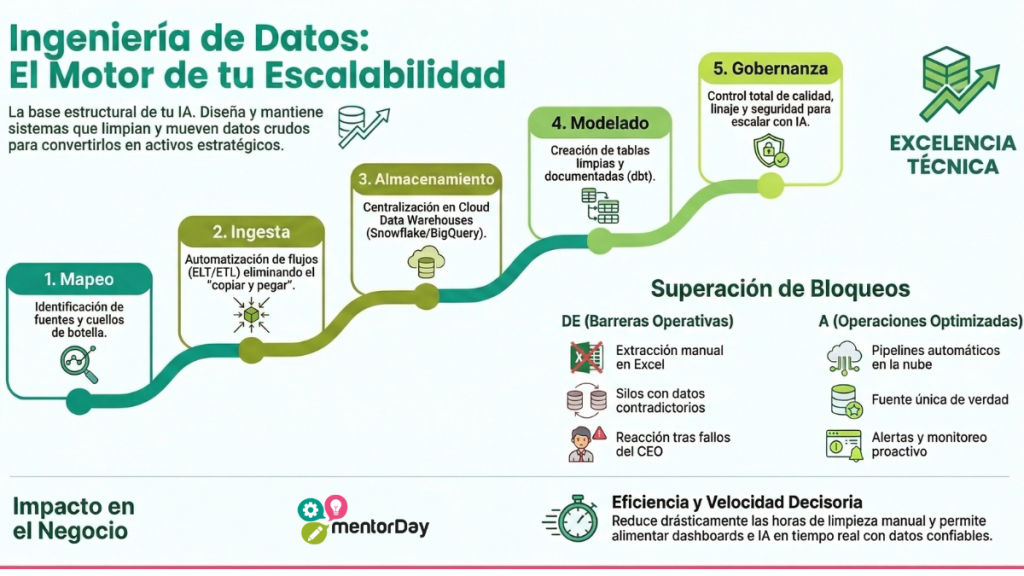
Definición y esencia:La Ingeniería de datos es la disciplina de diseñar, construir y mantener sistemas escalables para la recopilación, almacenamiento y procesamiento de datos. Es la base estructural que transforma datos crudos y caóticos en activos limpios y accesibles para analistas, modelos de machine learning e Inteligencia Artificial. NO es simplemente hacer gráficos en Excel, ni es ciencia de datos; es la fontanería e infraestructura de software que hace posible la analítica avanzada.
Explicación práctica:En la economía digital, los datos son el principal activo estratégico. Sin embargo, los datos generados por usuarios, APIs o sensores llegan desestructurados. Un emprendedor con esta competencia entiende cómo orquestar flujos de trabajo (pipelines ETL/ELT), diseñar esquemas de bases de datos y utilizar tecnologías en la nube para que la información fluya sin interrupciones, con alta calidad y seguridad. Es pasar de depender de procesos manuales a tener una «fábrica de datos» automatizada.
Comportamientos, conductas y hábitos del emprendedor:
- Pensamiento arquitectónico: Diseña soluciones pensando en el volumen futuro, no solo en el problema actual.
- Automatización por defecto: Rechaza las extracciones manuales; programa scripts (Python, SQL) para mover datos.
- Obsesión por la calidad del dato: Implementa reglas y tests para evitar que «basura» entre en el sistema (Garbage In, Garbage Out).
- Mentalidad «Data as a Product»: Trata los conjuntos de datos como productos finales con metadatos, descubribilidad y SLAs definidos.
Beneficios clave vinculados a resultados:
- ↑ Eficiencia operativa: Reducción drástica de horas invertidas en limpieza manual de reportes.
- ↑ Velocidad de decisión: Dashboards e IA alimentados en tiempo real con datos confiables.
- ↓ Costes de infraestructura: Optimización del almacenamiento y procesamiento en la nube (AWS, GCP).
- ↓ Riesgo de cumplimiento: Trazabilidad (linaje) y gobernanza que aseguran el cumplimiento de normativas (GDPR).
- ↑ Escalabilidad: Capacidad de absorber picos de tráfico y volumen de datos sin que el sistema colapse.
Micro-ejemplos de uso cotidiano:
- Crear un script en Python que extrae diariamente métricas de Stripe y las carga en BigQuery.
- Modelar un esquema en estrella en la base de datos para que las consultas de marketing tarden segundos en lugar de horas.
- Configurar alertas automatizadas si un flujo de datos (pipeline) falla durante la madrugada.
«Sin una sólida ingeniería de datos, cualquier modelo de Inteligencia Artificial es solo un castillo construido sobre arena.»
Por qué mejorarla acelera la empresa:
Te permite superar la fase de «validación manual» y entrar en la escalabilidad técnica. Cuando los datos fluyen automáticamente y son confiables, el equipo directivo toma decisiones precisas más rápido, y los equipos de IA pueden crear productos defendibles (fosos tecnológicos) que los competidores no pueden copiar fácilmente.
BLOQUE 2. AUTODIAGNÓSTICO – TU PUNTO DE PARTIDA
Indicadores conductuales observables:
- Orquesto el movimiento de mis datos de forma automatizada (no uso copiar/pegar). (Lo hago / A veces / No lo hago)
- Modelo la estructura de las bases de datos pensando en el rendimiento analítico. (Lo hago / A veces / No lo hago)
- Monitorizo los fallos de carga de datos mediante alertas automáticas. (Lo hago / A veces / No lo hago)
- Escribo código modular (SQL, Python) versionado en Git para mis pipelines de datos. (Lo hago / A veces / No lo hago)
- Conozco y aplico la separación entre almacenamiento y computación en la nube. (Lo hago / A veces / No lo hago)
Medición cuantitativa (KPIs):
- Tasa de fallo de pipelines: % de días en el mes que un flujo de datos falla. (Objetivo: < 2%).
- Latencia del dato: Tiempo que tarda un evento desde que ocurre hasta que está disponible para análisis.
- Cobertura de tests de datos: % de tablas principales que tienen tests de calidad automatizados.
Autoevaluación Likert (1-5):
(1 = Totalmente en desacuerdo, 5 = Totalmente de acuerdo)
- Domino el diseño de arquitecturas cloud (Data Warehouses / Data Lakes) para mi negocio. [ ]
- Utilizo herramientas avanzadas de transformación (ej. dbt, Spark) para limpiar y modelar mis datos. [ ]
- Comprendo a fondo las diferencias entre procesamiento batch y streaming (tiempo real). [ ]
- Aplico principios de gobierno del dato, linaje y seguridad de accesos en toda la empresa. [ ]
- Sé construir un pipeline ETL/ELT robusto desde cero conectando APIs a mi base de datos. [ ]
Cálculo de puntuación global:
- Fórmula: (Media de tus respuestas Likert – 1) × 25 = Puntuación 0-100.
- Umbrales:
- 0–39 Bajo: Dependes de procesos manuales; alto riesgo de silos.
- 40–59 Medio: Tienes bases de datos, pero la integración y automatización son frágiles.
- 60–79 Alto: Pipelines automatizados y arquitectura estructurada.
- 80–100 Excelente: «Data as a product», infraestructura de clase mundial, listo para escalar con IA.
Niveles de dominio:
- 1. Básico: Exporta CSVs y usa hojas de cálculo o bases de datos simples (MySQL/Postgres) sin automatización.
- 3. Intermedio: Automatiza cargas con Python/herramientas No-code, usa un Data Warehouse básico (ej. Snowflake) y modelado inicial.
- 5. Experto: Arquitectura distribuida (Kafka, Spark), control de versiones completo (Git, CI/CD para datos), Data Mesh, escalabilidad infinita y gobernanza total.
Mini SJT (Situational Judgment Test):
Situación 1: Tu equipo de marketing se queja de que los datos del dashboard de ventas de ayer están incompletos y algunos campos tienen errores de formato.
- A) Pides a un desarrollador que entre a la base de datos y corrija los registros a mano. (1 punto)
- B) Creas un script manual que descargas cada mañana, corriges en Excel y vuelves a subir. (0 puntos)
- C) Implementas una herramienta como Great Expectations o dbt dentro de tu pipeline para detectar y frenar datos anómalos antes de que lleguen al dashboard. (Respuesta correcta, 3 puntos)
Situación 2: Tienes decenas de fuentes de datos (CRM, Ads, ERP) y necesitas centralizarlas porque hacer cruces de datos es imposible.
- A) Contratas un software de integración (ej. Fivetran, Airbyte) para hacer un ELT automatizado hacia un Data Warehouse centralizado. (Respuesta correcta, 3 puntos)
- B) Creas consultas cruzadas directas a las APIs cada vez que alguien abre un reporte. (0 puntos – colapsarás las APIs y será lentísimo).
- C) Exportas todo a un Google Drive compartido y usas VLOOKUPs masivos. (1 punto – no escalable).
Red flags (4 alertas de peligro):
- Tus dashboards tardan más de 5 minutos en cargar por falta de modelado previo.
- Un empleado pasa más de 5 horas a la semana descargando y uniendo archivos.
- Existen tres números diferentes para las «ventas del mes» dependiendo del departamento al que preguntes.
- Si un script falla, nadie se entera hasta que el cliente o el CEO se queja.
Evidencias de dominio (4):
- Un Data Warehouse centralizado (Single Source of Truth).
- Orquestador de tareas implementado (ej. Apache Airflow, Mage).
- Documentación de linaje (saber exactamente de dónde viene cada métrica).
- Infraestructura operada mediante código (Infrastructure as Code).
BLOQUE 3. LA COMPETENCIA EN ACCIÓN – CASOS Y CONTEXTOS
Caso de éxito:
Situación: Una startup de e-commerce procesaba el comportamiento de usuarios de forma manual, dificultando la personalización.
Acción con Ingeniería de datos: El equipo migró a una arquitectura ELT con Snowflake, dbt y Airbyte. Crearon un pipeline de streaming para los clics en la web.
Resultado: Los modelos de recomendación se actualizaron casi en tiempo real, incrementando el ticket medio un 18% y reduciendo el coste de mantenimiento en servidores en un 40%.
Caso de carencia:
Situación: Una fintech basada en IA construyó algoritmos predictivos brillantes, pero dependían de datos extraídos por scripts caseros frágiles.
Falta:Carencia de monitorización y pruebas de calidad (Data Observability).
Consecuencia:Durante una semana, un cambio en la API de su proveedor de pagos hizo que entraran datos corruptos. El modelo recomendó préstamos de alto riesgo asumiendo perfiles impecables, generando pérdidas severas.
Aprendizaje: Adoptaron contratos de datos estrictos y MLOps para separar la infraestructura de producción de la experimentación.
Dónde es más necesaria (Matriz Fase × Sector):
Fase del proyecto | Sector / Modelo | Criticidad (A/M/B) | Justificación |
|---|
Validación | Tech (B2B SaaS) | Medio | Es necesario tener un pipeline limpio inicial, pero prima la velocidad del MVP. |
Crecimiento | E-commerce / Retail | Alto | Volumen de transacciones alto; sin integración, el CAC y LTV no se pueden optimizar. |
Escala | IA / Machine Learning | Alto | Los modelos devoran datos; la latencia y la calidad son de vida o muerte para el producto. |
Escala | Fintech / Health | Alto | La gobernanza, seguridad y linaje de datos son requisitos regulatorios ineludibles. |
Idea | Servicios tradicionales | Bajo | Inicialmente, un CRM empaquetado o herramientas no-code estándar son suficientes. |
Crecimiento | Plataformas IoT | Alto | El procesamiento masivo de datos en tiempo real (Kafka) exige arquitecturas complejas. |
Perfiles de emprendedor para los que es crítica:
CTOs, perfiles técnicos (Founders) de startups DeepTech o IA, y líderes de operaciones (COOs) en empresas orientadas a producto (Product-Led Growth). Especialmente aquellos escalando modelos de negocio basados en el uso intensivo de datos, donde la monetización del dato es el core.
Cuándo NO es prioritaria:
- Fase «Idea» sin validación de mercado: Crear un clúster de Spark antes de tener tu primer cliente es over-engineering fatal.
- Micropymes locales de servicios presenciales: Si el volumen de datos cabe en un Excel y no es tu ventaja competitiva diferencial.
BLOQUE 4. PLAN DE ENTRENAMIENTO – CÓMO MEJORAR
En la 1.ª etapa del programa mentorDay, identificarás si la infraestructura de datos es una competencia esencial para la escalabilidad de tu negocio y tendrás 1 mes para incorporar estos hábitos.En la 2.ª etapa, vuelve a autovalorarte; si la curva de aprendizaje técnica es muy alta, decide buscar un CTO o Data Engineer que la aporte, con ayuda de tu mentor asignado. Tendrás talleres y speedmentoring con expertos.
5 micro-hábitos accionables (≤1 min):
- Duda del origen: Antes de analizar una métrica, pregunta «¿De qué tabla/API exacta viene y cuándo se actualizó?».
- No sobrescribas, anexa: Haz costumbre guardar el histórico de datos en tus sistemas, nunca borres sin dejar rastro de auditoría.
- Documenta un campo diario: Cada vez que uses una columna confusa en tu base de datos, entra al diccionario de datos y escribe su significado real.
- Revisa logs matutinos: Tómate 1 minuto para ver el panel de tu orquestador de datos y confirmar que todo está «en verde».
- Aplica naming conventions: Llama a tus variables y tablas con lógica estandarizada (ej.
fct_ventas, dim_clientes).
3 ejercicios paso a paso:
Ejercicio 1: Mapeo de la arquitectura de datos (Data Lineage)
- Objetivo: Visualizar de dónde vienen y a dónde van tus datos.
- Duración: 45 mins. Materiales: Pizarra o Miro.
- Instrucciones: Dibuja en la izquierda todas las fuentes (APIs, Web, CRM). En el centro, cómo se almacenan. En la derecha, dónde se consumen (BI, apps). Traza flechas de conexión e identifica cuellos de botella manuales.
- Criterio de éxito: Mapa claro identificando al menos 2 procesos que requieren automatización urgente.
- Variante exprés (10 min): Haz el mapeo solo para tu métrica de negocio más importante («la North Star Metric»).
Ejercicio 2: Tu primer pipeline ELT (Extract, Load, Transform)
- Objetivo: Entender la lógica técnica de mover datos.
- Duración: 2 horas. Materiales: Cuenta gratuita de Airbyte o Fivetran y BigQuery/Snowflake.
- Instrucciones: Conecta una fuente (ej. Google Ads) a un Data Warehouse destino configurando la frecuencia diaria. Revisa cómo los datos llegan en bruto y escribe una query SQL para normalizarlos.
- Criterio de éxito: Carga exitosa automatizada.
- Variante exprés (10 min): Ver un tutorial técnico de integración en la nube y replicar conceptualmente la conexión.
Ejercicio 3: Contrato de Datos (Data Contract)
- Objetivo: Asegurar la calidad semántica en el equipo.
- Duración: 30 mins. Materiales: Google Docs.
- Instrucciones: Reúne al que genera el dato (ej. Dev de producto) y al que lo consume (Analista). Escriban un acuerdo formal sobre 5 campos críticos (tipo de dato, si permite nulos, qué significa).
- Criterio de éxito: Documento firmado por ambas partes evitando futuras roturas de pipelines.
- Variante exprés (10 min): Define y documenta el contrato solo para el «Email del cliente».
Frameworks y metodologías:
- Modern Data Stack (MDS): Arquitectura basada en la nube (Cloud Data Warehouse, ELT, herramientas SaaS).
- Medallion Architecture: Patrón (Bronce: Crudos -> Plata: Limpios -> Oro: Analíticos) para procesar datos en capas.
- Data Mesh / Data Fabric: Modelos de descentralización y tratamiento del «Dato como Producto».
Errores comunes y anti-patrones:
- Crear ETL rígidos y frágiles: Programar scripts monolíticos que se rompen con cualquier mínimo cambio en la API origen. Solución: Usa herramientas ELT estándar.
- No separar cómputo y almacenamiento: Solución: Usa arquitecturas Cloud-native (Snowflake, BigQuery).
- Consultas analíticas en la BBDD transaccional: Solución: Crea réplicas o almacenes analíticos (Data Warehouse) para no tirar la web principal.
- Silos de datos departamentales: Finanzas tiene sus datos, Marketing los suyos. Solución: Repositorio único (Single Source of Truth).
- Ignorar la privacidad (PII): Mover datos sensibles en texto plano. Solución: Enmascarar datos (Data Masking) desde la ingesta.
BLOQUE 5. HERRAMIENTAS Y RECURSOS DE APOYO
Recomendación principal:Regístrate en el programa de aceleración de mentorDay para identificar las competencias tecnológicas clave de tu perfil. Aprende de mentores expertos en arquitectura tecnológica y escalabilidad en la nube.
En la 3.ª etapa, se te asignará un mentor técnico especializado para guiar la evolución de tu stack de datos. Info: Programa Mentoring Plantillas y Apps:
- Airbyte / Fivetran / Trocco: Plataformas SaaS esenciales para automatizar la extracción y carga (ingesta) sin apenas programar.
- dbt (Data Build Tool): El estándar de la industria para transformar y testear datos usando SQL modular y control de versiones.
- Snowflake / Google BigQuery: Data Warehouses en la nube que separan computación de almacenamiento.
- Apache Airflow / Mage.ai: Orquestadores para planificar y monitorizar flujos de datos.
Lecturas clave:
- Fundamentals of Data Engineering por Joe Reis y Matt Housley. Por qué: Es «la biblia» moderna que desmitifica el ciclo de vida completo de la ingeniería de datos sin atarte a una tecnología específica.
- Designing Data-Intensive Applications por Martin Kleppmann. Por qué: Lectura profunda para entender arquitecturas de software y sistemas distribuidos.
Formación recomendada:
- Data Engineering Zoomcamp (DataTalks.Club): Nivel Intermedio/Avanzado. Curso gratuito y completo sobre GCP, Terraform, Spark, Airflow y Kafka.
- Certificaciones oficiales en la nube: Nivel Básico/Intermedio. «AWS Certified Data Engineer» o «Google Cloud Professional Data Engineer».
Contenidos mentorDay:
- No olvides revisar recursos formativos adicionales y webinars en la plataforma. Te invitamos a suscribirte a los canales de YouTube de mentorDay y a su newsletter.
BLOQUE 6. ECOSISTEMA DE APOYO – COMPLEMENTA TU PERFIL
Si te das cuenta de que la Ingeniería de datos es excesivamente técnica para ti y te frena operativamente, busca un socio técnico o un perfil especializado.
Perfiles complementarios:
- Data Engineer / Arquitecto Cloud: Compensa tu visión de negocio construyendo la infraestructura escalable real. Tarea a delegar: Desarrollo de pipelines, orquestación y mantenimiento del Data Warehouse.
- Data Analyst / Analytics Engineer: Compensa modelando los datos limpios y extrayendo insights accionables. Tarea a delegar: Creación de dashboards y modelos de datos con dbt y SQL.
- Data Scientist / ML Engineer: Aplica IA sobre los datos que el ingeniero ha preparado. Tarea a delegar: Modelado predictivo y MLOps.
Checklist para identificar e integrar perfiles:
- [ ] Valora su experiencia montando infraestructuras desde cero, no solo manteniendo las ya creadas.
- [ ] Evalúa sus habilidades en SQL (imprescindible) y Python.
- [ ] Pregunta por su enfoque sobre la «Gobernanza de Datos» y calidad, no solo en velocidad de entrega.
- [ ] Fomenta que trabaje estrechamente con operaciones; los ingenieros de datos deben ser traductores de negocio, no solo picadores de código.
Comunidades y Redes para practicar:
- Locally Optimistic / dbt Slack Community: Para estar a la última en el Modern Data Stack.
- Reddit r/dataengineering: Discusiones crudas y reales sobre problemas arquitectónicos.
- Meetups de Data Engineering locales: Presenciales para contactar talento.
- Networking mensual de mentorDay: Conecta con perfiles técnicos que buscan proyectos empresariales donde aportar. 👉 Networking online mentorDay
BLOQUE 7. TU PLAN DE ACCIÓN PERSONAL
Objetivo SMART a 30 días:
Ejemplo: «Automatizar la ingesta diaria de las 3 principales fuentes de datos (CRM, Ads, ERP) en un Data Warehouse centralizado usando una herramienta No-code, reduciendo a cero las horas de extracción manual antes del fin de mes.»
Plan 30–60–90:
Fase | Metas semanales / mensuales | Métricas (KPIs) | Entregables |
|---|
Día 30 | Mapear arquitectura actual e implementar ingesta automatizada (EL). | Horas manuales reducidas. Fuentes conectadas. | Diagrama de linaje. Warehouse activo con datos crudos. |
Día 60 | Implementar transformación y modelado básico (dbt). | Tiempo de carga de consultas BI. Tablas limpias creadas. | Esquemas en estrella documentados. Datos limpios en producción. |
Día 90 | Automatizar tests de calidad y orquestación con alertas. | % Cobertura de tests. Fallos no detectados = 0. | Pipeline completo documentado y operando sin intervención. |
KPIs de progreso adicionales:
- % de automatización de reportes de la empresa.
- Disponibilidad y Up-time del sistema de datos.
- Costo mensual de infraestructura vs. valor generado.
Próximo paso en 5 minutos:
Haz un boceto rápido a lápiz de todas las fuentes de datos (SaaS, Excel, web) que necesita tu empresa hoy para funcionar. Identifica cuál es la más crítica que hoy requiere «mano de obra» y márcala con un círculo rojo.
Copia y pega tu resumen en el área privada y en el entregable ‘Plan de recursos humanos, desarrollo y crecimiento personal’ del programa mentorDay.
BLOQUE 8. MAPA DE ADECUACIÓN ESTRATÉGICA DE Ingeniería de datos
(Contexto: La Ingeniería de Datos es crítica en fases de Crecimiento y Escala, especialmente en modelos SaaS, Ecommerce y productos basados en IA. Es el habilitador técnico principal para organizaciones «Data-Driven» y de inteligencia artificial).
8.1. Cuándo aplicar:
- Decenas de fuentes fragmentadas → Aporta valor unificando silos para dar una visión de negocio en 360 grados.
- Caos en la veracidad de reportes → Restaura la confianza en los datos eliminando el factor humano en la extracción.
- Implementación inminente de IA → Proporciona la canalización de datos estructurados, de alta velocidad, indispensable para entrenar modelos sin sesgos.
- Altos costes de servidores → La separación de almacenamiento y cómputo optimiza la factura mensual.
8.2. Dónde es más necesaria (Matriz Fase × Sector × Modelo × Innovación):
Sector | Modelo de negocio | Fase del proyecto | Grado de innovación | Criticidad | Justificación (≤1 línea) |
|---|
SaaS / IA | Suscripción | Escala | Radical / Disruptiva | Alto | Los modelos de IA colapsan si no tienen canales de datos automatizados y limpios. |
Retail / Ecom | Venta directa | Crecimiento | Incremental | Alto | Volumen transaccional alto exige automatizar el análisis de LTV, CAC e inventario. |
Impacto | Marketplace | Validación | Sustancial | Medio | Requiere medir el equilibrio de oferta y demanda, pero admite aún procesos semi-manuales. |
Salud / Biotech | B2B | Crecimiento | Radical | Alto | Exigencia de gobierno de datos, privacidad e integración de historias clínicas a gran escala. |
Servicios Prof. | Consultoría | Idea | Incremental | Bajo | Escaso volumen inicial; un CRM básico es suficiente sin montar arquitecturas costosas. |
IoT / Ind. 4.0 | HW + Servicio | Crecimiento | Disruptiva | Alto | Millones de eventos por segundo (sensores) exigen tecnología de streaming avanzada. |
8.3. Tecnologías a incorporar:
- Data Warehouse (Snowflake / BigQuery) → Repositorio central escalable para almacenamiento analítico.
- ETL/ELT SaaS (Fivetran / Airbyte / Trocco) → Ingesta y conexión automatizada de cientos de APIs en minutos.
- Transformación (dbt) → Limpieza, pruebas y modelado colaborativo aplicando control de versiones (Git).
- Orquestación (Airflow / Mage) → Coordinación de horarios y dependencias de ejecución de las tuberías de datos.
- Streaming (Apache Kafka) → Manejo y procesamiento de datos masivos en tiempo real.
- Catálogo y Gobernanza (Alation / Collibra) → Diccionarios de datos para trazabilidad y cumplimiento legal.
8.4. Tamaño y economía del proyecto:
Variable | Rango recomendado | Umbral de prioridad | Nota / por qué |
|---|
Tamaño de equipo | 1–2 · 3–10 · 11–50 · 51–200 · >200 | >10 personas | Al existir múltiples departamentos, la «única fuente de verdad» es obligatoria. |
Facturación anual | 0–100k · 100k–500k · 500k–2M · 2M–10M · >10M | >500k € | El coste de las decisiones basadas en datos erróneos escala rápidamente. |
Volumen de Datos | MBs · GBs · Terabytes · Petabytes | >50 GB / Terabytes | Excel y bases de datos transaccionales simples colapsan; urge Big Data. |
Forma de ingresos | One-off · Suscripción · Usage · Ads | Usage / Ads / Sub | Medir uso (telemetría) o renovaciones en masa requiere infraestructura sólida. |
8.5. Reglas de decisión e Índice de Adecuación (IA):
- Puntuación por dimensión: Alto = 3 | Medio = 2 | Bajo = 1.
- Fórmula IA: (Sector·0,25 + Modelo·0,25 + Fase·0,25 + Innovación·0,25).
- Ajustes (+0,2 c/u):
- Innovación Radical (ej. modelos IA propios).
- Ingresos Usage-based (pago por uso) o suscripciones masivas.
- Modelo B2B2C o Marketplace con alta complejidad de cruce de datos.
- Umbrales:IA ≥ 2,6 → ALTA | 2,0–2,59 → MEDIA | < 2,0 → BAJA.
- Conclusión operativa: Si tu IA es Alta, debes externalizar o contratar talento en Ingeniería de datos de inmediato; seguir usando procesos manuales destruirá tu capacidad operativa y rentabilidad a corto plazo. Si es Baja, prioriza traccionar ventas con herramientas estándar.
8.6. Siguiente paso:
- Abre tu panel actual de analíticas (Google Analytics o CRM) y verifica qué % de su información actual requiere manipulación humana para ser útil. Si es mayor al 20%, entra al programa mentorDay para diseñar tu automatización.
RESUMEN EJECUTIVO Y EXTRAS
Tabla-resumen ejecutiva:
Qué es | Cómo medir | Riesgos si es baja | 3 hábitos | 3 ejercicios | 3 herramientas |
|---|
Diseño de arquitecturas para mover, limpiar y procesar datos a escala para analytics e IA. | Tasa de fallos en pipelines, latencia de datos y tiempos de carga de consultas SQL. | Decisiones erróneas por datos corruptos, imposibilidad de entrenar IA, colapso de servidores. | 1. Trazar el origen del dato. 2. Documentar diccionarios. 3. Alertas automatizadas. | 1. Mapeo Data Lineage. 2. Montar pipeline ELT básico. 3. Firmar Contratos de Datos. | 1. Snowflake/BigQuery (Storage) 2. dbt (Transformación) 3. Airflow/Mage (Orquestador) |
Mapa de riesgos:
- Operativo: Los equipos comerciales y de marketing toman decisiones con datos obsoletos; el coste de mantenimiento se dispara.
- Equipo: Agotamiento (burnout) del equipo técnico haciendo trabajos repetitivos de limpieza y perdiendo foco en la innovación.
- Mercado: Competidores con infraestructura escalable pueden usar IA para optimizar precios y retención mucho más rápido que tú.
Sectores/fases donde NO es clave:
- Validación de servicios físicos: Tiendas locales o despachos profesionales. Alternativa: SaaS como HubSpot o Shopify que ya traen analíticas integradas.
- Etapa Seed pre-producto: El volumen de datos no justifica inversión de servidor. Alternativa: Airtable, Zapier o Excel avanzado.
Competencias relacionadas (mapa mentorDay):
- Alfabetización tecnológica: Prerrequisito absoluto.
- Capacidad analítica: Es el complemento (el análisis extrae valor de la infraestructura).
- Programación informática / Ciberseguridad: Habilidades técnicas adyacentes para programar scripts y asegurar la privacidad del dato.
Enlaces internos sugeridos a otras WikiTIPS: